Carry Skip Adder Verilog Code
16 bit Carry Bypass Adder Verilog Code
A carry-skip adder (also known as a carry-bypass adder) is an adder implementation that improves on the delay of a ripple-carry adder with little effort compared to other adders. The improvement of the worst-case delay is achieved by using several carry-skip adders to form a block-carry-skip adder. For more information about carry bypass adder you can refer to this wikipedia article.
Basic structure of 4-bit Carry Skip/Bypass Adder is shown below.
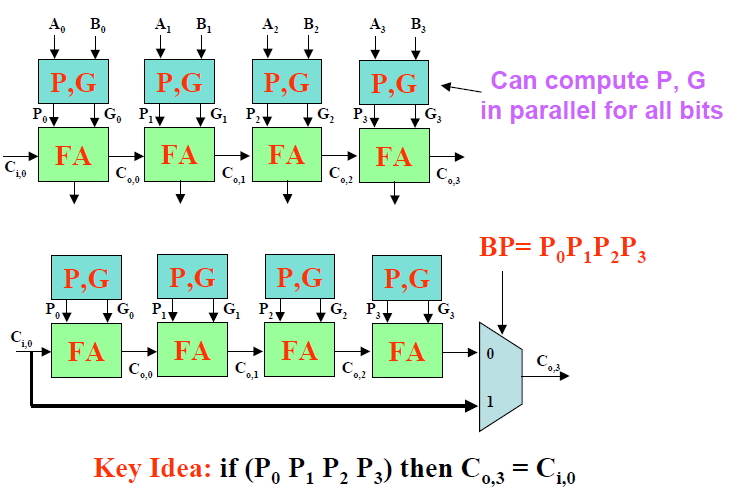
The Verilog Code for 16-bit Carry Skip Adder is given below-
`timescale 1ns / 1ps module carry_skip_16bit(a, b, cin, sum, cout); input [15:0] a,b; input cin; output cout; output [15:0] sum; wire [2:0] c; carry_skip_4bit csa1(.a(a[3:0]), .b(b[3:0]), .cin(cin), .sum(sum[3:0]), .cout(c[0])); carry_skip_4bit csa2 (.a(a[7:4]), .b(b[7:4]), .cin(c[0]), .sum(sum[7:4]), .cout(c[1])); carry_skip_4bit csa3(.a(a[11:8]), .b(b[11:8]), .cin(c[1]), .sum(sum[11:8]), .cout(c[2])); carry_skip_4bit csa4(.a(a[15:12]), .b(b[15:12]), .cin(c[2]), .sum(sum[15:12]), .cout(cout)); endmodule ///////////////////////////////////// // Carry Skip Adder 4 bit ////////////////////////////////////// module carry_skip_4bit(a, b, cin, sum, cout); input [3:0] a,b; input cin; output [3:0] sum; output cout; wire [3:0] p; wire c0; wire bp; ripple_carry_4_bit rca1 (.a(a[3:0]), .b(b[3:0]), .cin(cin), .sum(sum[3:0]), .cout(c0)); generate_p p1(a,b,p,bp); mux2X1 m0(.in0(c0),.in1(cin),.sel(bp),.out(cout)); endmodule ///////////////////////////////////// // Propagate Generation ///////////////////////////////////// module generate_p(a,b,p,bp); input [3:0] a,b; output [3:0] p; output bp; assign p= a^b;//get all propagate bits assign bp= &p;// and p0p1p2p3 bits endmodule ///////////////////////////////// //4-bit Ripple Carry Adder ///////////////////////////////// module ripple_carry_4_bit(a, b, cin, sum, cout); input [3:0] a,b; input cin; wire c1,c2,c3; output [3:0] sum; output cout; full_adder fa0(.a(a[0]), .b(b[0]),.cin(cin), .sum(sum[0]),.cout(c1)); full_adder fa1(.a(a[1]), .b(b[1]), .cin(c1), .sum(sum[1]),.cout(c2)); full_adder fa2(.a(a[2]), .b(b[2]), .cin(c2), .sum(sum[2]),.cout(c3)); full_adder fa3(.a(a[3]), .b(b[3]), .cin(c3), .sum(sum[3]),.cout(cout)); endmodule /////////////////////////////////////////// //1bit Full Adder ////////////////////////////////////////// module full_adder(a,b,cin,sum, cout); input a,b,cin; output sum, cout; wire x,y,z; half_adder h1(.a(a), .b(b), .sum(x), .cout(y)); half_adder h2(.a(x), .b(cin), .sum(sum), .cout(z)); or or_1(cout,z,y); endmodule ///////////////////////////////////////////////////////////////////////////// // 1 bit Half Adder ////////////////////////////////////////////////////////////////////// module half_adder( a,b, sum, cout ); input a,b; output sum, cout; xor xor_1 (sum,a,b); and and_1 (cout,a,b); endmodule ///////////////////////// //2X1 Mux ///////////////////////// module mux2X1( in0,in1,sel,out); input in0,in1; input sel; output out; assign out=(sel)?in1:in0; endmodule
Carry Skip Adder Simulation Results:

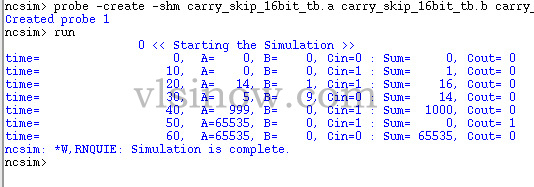
Cadence RTL compiler is used to synthesize the Carry Skip Adder verilog code with Uofu standard library. We got the following schematic after mapping the hdl code to the standard library. This is basically the synthesized view.
16 Bit Module

4-bit Module:

2X1 MUX Module:
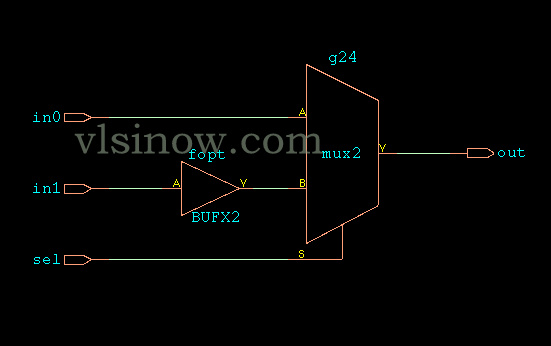
If you have any query/suggestion please feel free to comment below the post.
Can you please provide the test bench as well for Xilinx.