Carry Look Ahead Adder Verilog Code
16 bit Carry Look Ahead Adder
Carry look ahead adder is a fast adder architecture. In Ripple Carry Adder output carry depends on previous carry . But in carry look ahead adder the output carry is function of input bits and initial carry only. So output carry is calculated with combinational logic without waiting for previous carry. For more information about carry look ahead adder you can refer to this wikipedia article.
A carry-lookahead adder (CLA) or fast adder is a type of adder used in digital logic. A carry-lookahead adder improves speed by reducing the amount of time required to determine carry bits. It can be contrasted with the simpler, but usually slower, ripple carry adder for which the carry bit is calculated alongside the sum bit, and each bit must wait until the previous carry has been calculated to begin calculating its own result and carry bits (see adder for detail on ripple carry adders). The carry-lookahead adder calculates one or more carry bits before the sum, which reduces the wait time to calculate the result of the larger value bits.
Basic structure of 4-bit Carry Look Ahead Adder is shown below.

The Verilog Code for 16-bit Carry Look Ahead Adder is given below-
/////////////////////////////////////////////////////////// //16-bit Carry Look Ahead Adder /////////////////////////////////////////////////////////// `timescale 1ns / 1ps module carry_look_ahead_16bit(a,b, cin, sum,cout); input [15:0] a,b; input cin; output [15:0] sum; output cout; wire c1,c2,c3; carry_look_ahead_4bit cla1 (.a(a[3:0]), .b(b[3:0]), .cin(cin), .sum(sum[3:0]), .cout(c1)); carry_look_ahead_4bit cla2 (.a(a[7:4]), .b(b[7:4]), .cin(c1), .sum(sum[7:4]), .cout(c2)); carry_look_ahead_4bit cla3(.a(a[11:8]), .b(b[11:8]), .cin(c2), .sum(sum[11:8]), .cout(c3)); carry_look_ahead_4bit cla4(.a(a[15:12]), .b(b[15:12]), .cin(c3), .sum(sum[15:12]), .cout(cout)); endmodule //////////////////////////////////////////////////////// //4-bit Carry Look Ahead Adder //////////////////////////////////////////////////////// module carry_look_ahead_4bit(a,b, cin, sum,cout); input [3:0] a,b; input cin; output [3:0] sum; output cout; wire [3:0] p,g,c; assign p=a^b;//propagate assign g=a&b; //generate //carry=gi + Pi.ci assign c[0]=cin; assign c[1]= g[0]|(p[0]&c[0]); assign c[2]= g[1] | (p[1]&g[0]) | p[1]&p[0]&c[0]; assign c[3]= g[2] | (p[2]&g[1]) | p[2]&p[1]&g[0] | p[2]&p[1]&p[0]&c[0]; assign cout= g[3] | (p[3]&g[2]) | p[3]&p[2]&g[1] | p[3]&p[2]&p[1]&g[0] | p[3]&p[2]&p[1]&p[0]&c[0]; assign sum=p^c; endmodule
16 bit Carry Look Ahead Adder Testbench
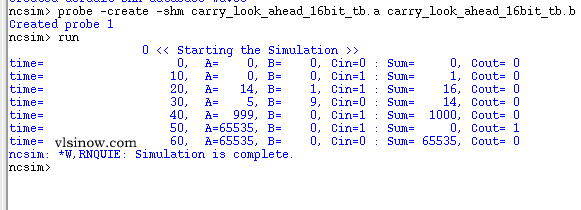
////Testbench module carry_look_ahead_16bit_tb; reg [15:0] a,b; reg cin; wire [15:0] sum; wire cout; carry_look_ahead_16bit uut(.a(a), .b(b),.cin(cin),.sum(sum),.cout(cout)); initial begin a=0; b=0; cin=0; #10 a=16'd0; b=16'd0; cin=1'd1; #10 a=16'd14; b=16'd1; cin=1'd1; #10 a=16'd5; b=16'd0; cin=1'd0; #10 a=16'd999; b=16'd0; cin=1'd1; end initial $monitor( "A=%d, B=%d, Cin= %d, Sum=%d, Cout=%d", a,b,cin,sum,cout); endmodule
Carry Look Ahead Adder Simulation Result is as follows:

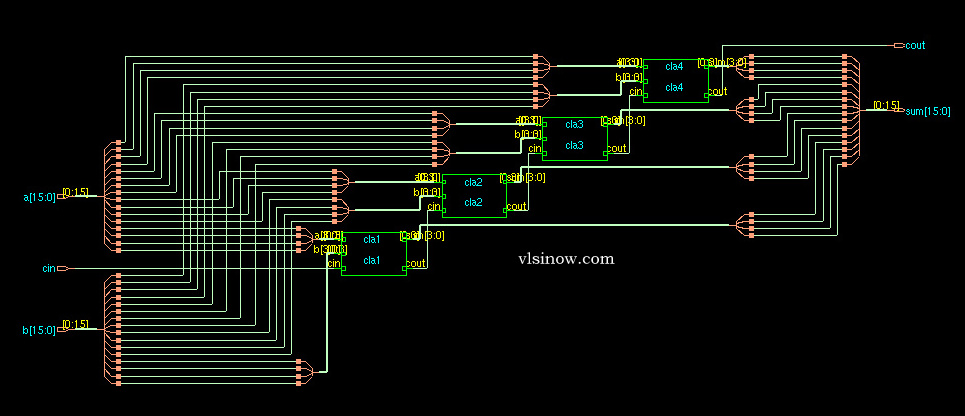
Cadence RTL compiler is used to synthesize the verilog code with Uofu standard library. We got the following schematic after mapping the hdl code to the standard library. This is basically the synthesized view.
If you have any query/suggestion please feel free to comment below the post.
In 4-bit carry look ahead, one line is incorrect:
**incorrect** assign cout= g[3] | (p[3]&g[2]) | p[3]&p[2]&g[1] | p[3]&p[2]&p[1]&p[0]&c[0];
**Corrected** assign cout= g[3] | (p[3]&g[2]) | p[3]&p[2]&g[1] | p[3]&p[2]&p[1]&g[0] | p[3]&p[2]&p[1]&p[0]&c[0];
This was probably a typographical error, but I want to point it out for anyone having trouble using this code
Thanks for visiting. But I want to clarify, the code given here is completely correct. After your comment, I simulated it again and found that it’s running perfectly. So, there is no need to update the code. Also, you can run the code in Edaplayground. Here is the link –> https://www.edaplayground.com/x/6DW8 . Thanks –Admin
I did it. code is correct
I am trying this code in the Xilinx_ISE_DS_Win_14.7_1015_1 but iam not getting the ouput.
Code is wrong and testbench is very poor quality for testing no wonder there are bugs in design you need to fix your main 16bit adder. Person below linked edaplayground code, you can modify it and see it doesnt work. A=3635, B=77d4 testbench should get correct answer of 0ae09 but the dut returns 0ad09. Top-level 16bit should not send carry from 4bit to each other in c1c2c3c4, you need to reuse carry select unit logic to generate c0 c1 c2 c3 instead with p and g from 4-bit adders.
Hi Mathieu, you are correct. Even Miles was also correct. There is one term missing in cout calculation. Thanks for pointing out. I have updated the code with the correction.
hi i need 6 bit carrylook ahead code with test bench can you please provide it
please do 6 bit carrylook ahead adder code please its a request
nice